[SQL 문법]
1. <SELECT> 키워드 : 데이터를 선택하는 키워드
Q1. 특정 테이블이 가진 모든(*) 컬럼(Field)를 가져와라
>> SELECT * FROM 테이블명;
Q2. 특정 테이블에서 특정 컬럼을 가져오기
>> SELECT 컬럼명 FROM 테이블명;
Q3. 특정 테이블에서 특정 컬럼과 다른 값 가져오기
>> SELECT DISTINCT 컬럼명 FROM 테이블명;
2. <WHERE> 키워드 : 테이블의 특정 컬럼 데이터 중, 조건에 충족한 레코드만을 추출.
Q1. 테이블 A의 컬럼B의 값이 C인 데이터를 가져와라
SELECT * FROM A
WHERE B = C;
Q2. 특정 테이블A에서 B컬럼의 값이 C가 아닌 데이터 가져오기
SELECT * FROM A
WHERE NOT B = C;
Q3. 특정 테이블A에서 컬럼B 값이 1, 컬럼C 값이 2 인 데이터를 가져와라
SELECT * FROM A
WHERE A = 1
AND B=2;
Q4. 특정 테이블A에서 컬럼 B 값이 1 이거나 컬럼 C 값이 2 인 경우
SELECT * FROM A
WHERE B = 1
OR C = 2;
3. < ORDER BY > 키워드 : 데이터 값을 정렬하는 역할 // ASC : 오름차순, DESC 내림차순
Q1. 테이블A에서 컬럼B의 값을 오름차순으로 가져오기.
SELECT * FROM A
ORDER BY B;
Q2. 테이블A에서 컬럼B의 값을 내림차순으로 가져오기.
SELECT * FROM A
ORDER BY B DESC;
Q3. 테이블A에서 오름차순으로 데이터를 가져오고 컬럼B 기준으로 중복된다면 컬럼C를 기준으로 가져온다.
SELECT * FROM A
ORDER BY B, C;
4. <INSERT INTO> 키워드 : 이미 존재하는 테이블에 새로운 레코드(row, 행)을 삽입
INSERT INTO 테이블명
(추가할_기존의컬럼1, 추가할_기존의컬럼2, 추가할_기존의컬럼3)
VALUES (추가할_값1, 추가할_값2, 추가할_값3);
5. <NULL> 키워드 : 값이 없는 필드(컬럼) 찾기
Q1. 테이블 A의 데이터 중 컬럼명B이 빈 상태인 데이터를 불러오라
SELECT * FROM A
WHERE B IS NULL;
Q2. 테이블A의 컬럼들 중 컬럼A가 빈 상태가 아닌 데이터를 불러와라
SELECT * FROM A
WHERE B IS NOT NULL;
6. <UPDATE SET> 키워드 : 기존 레코드를 변경할 때
기본 구조
UPDATE 테이블
SET 바꿀_컬럼명 = 새로운_값;
Q1. 테이블A에서 컬럼명B의 값이 2인 데이터의 컬럼명C의 값을 3으로 바꾼다.
UPDATE A
SET C = 3
WHERE B =2
Q2. 테이블A에서 컬럼명B의 값을 2, 컬럼명C의 값을 3으로 바꾼다.
UPDATE A
SET B = 2, C = 3;
7. <DELETE> 키워드 : 기존 레코드를 삭제할 때
Q1. 테이블A의 모든 행 중에 B라는 값을 가진 컬럼 C를 지워라.
DELETE FROM A
WHERE C = B;
8. <FUNCTION> 키워드 : 최소 값, 최대 값, 총 개수, 평균 값, 합계 구하는 키워드
Q1. 테이블A 에서 컬럼B의 값들 중 가장 작은 값을 가져와라.
SELECT MIN (B)
FROM A;
Q2. 테이블A 에서 B컬럼의 값들 중 가장 큰 값을 가져와라.
SELECT MAX (B)
FROM A;
Q3. 테이블A 에서 B컬럼의 값이 C인 개수를 가져와라
SELECT COUNT (*)
FROM A
WHERE B = C;
Q4. 테이블 A에서 B컬럼의 평균 값을 가져와라.
SELECT AVG(B)
FROM A;
Q5. 테이블 A의 B 컬럼의 합계를 가져와라
SELECT SUM(B)
FROM A;
9. <LIKE> 키워드 : 지정된 패턴을 검색하기 위해 사용
Q1. 테이블A의 컬럼B의 값들 중 A로 시작하는 값을 가져와라.
SELECT *
FROM A
WHERE B LIKE 'A%';
Q2. 테이블 A의 컬럼 B 값들 중 C로 끝나는 값을 가져와라
SELECT *
FROM A
WHERE B LIKE '%C';
Q3. 테이블 A의 컬럼 B 값들 중 C를 가진 값들을 가져와라
SELECT *
FROM A
WHERE B LIKE '%C%';
Q4. 테이블 A의 컬럼 B 값들 중 C로 시작하거나 D로 끝나는 값들을 가져와라
SELECT *
FROM A
WHERE B LIKE 'C%D';
Q5. 테이블 A의 컬럼 B 값들 중 C로 시작하지 않는 값들을 가져와라.
SELECT *
FROM A
WHERE B NOT LIKE 'C%';
10. <Wildcards> 키워드 : 하나 이상의 문자를 대체 혹은 지정된 패턴을 검색
Q1. 테이블A의 컬럼B의 값들 중 A가 두번째에 포함된 값을 가져와라.
SELECT *
FROM A
WHERE B LIKE '_A%';
Q2. 테이블A의 컬럼B의 값들 중 C or D or E로 시작하는 값을 가져와라.
SELECT *
FROM A
WHERE B LIKE '[CDE%]';
Q3. 테이블A의 컬럼B의 값들 중 A ~ F로 시작하는 값을 가져와라.
SELECT *
FROM A
WHERE B LIKE '[A-F%]';
Q4. 테이블A의 컬럼B의 값들 중 C or D or E가 첫번째 문자가 아닌 값을 가져와라.
SELECT *
FROM A
WHERE B LIKE '[!CDE%]';
11. <SQL IN> 키워드 : 특정 컬럼에 여러 값을 지정할 수 있다.
Q1. 테이블A의 컬럼B의 값이 1 or 2인 값을 가져와라
SELECT *
FROM A
WHERE B IN (1, 2);
Q2. 테이블A의 컬럼B의 값이 1 or 2가 포함되지 않은 값을 가져와라
SELECT *
FROM A
WHERE B NOT IN (1, 2);
12. <SQL BETWEEN> 키워드 : 주어진 범위 내에서 값을 선택 (숫자, 문자, 날짜)
Q1. 테이블A의 컬럼B의 값이 10과 20 사이인 데이터를 가져와라
SELECT *
FROM B
WHERE B BETWEEN 10 AND 20;
Q1. 테이블A의 컬럼B의 값이 10과 20 사이가 아닌 데이터를 가져와라
SELECT *
FROM B
WHERE B NOT BETWEEN 10 AND 20;
13. <SQL ALIAS> 키워드 : 테이블 또는 테이블의 컬럼(열)에 임시 이름을 지정하는데 사용 // AS ~
Q1. 테이블A의 컬럼들 중 컬럼 B을 C 라고 부르겠다.
SELECT B AS C
FROM A;
Q2. 테이블A를 테이블 B 라고 부르겠다.
SELECT *
FROM A AS B;
14. <SQL JOIN> 키워드 : 테이블 간의 관계를 나타내는 키워드
[OUTER JOIN]
<LEFT JOIN>
좌측 테이블을 기준으로 일치하는 행만 결합되고, 일치하지 않는 부분은 null 값으로 채워진다.
[작성 형식]
SELECT *조회할 컬럼*
FROM *기준테이블*
LEFT JOIN *대상 테이블*
ON A.컬럼1 = B.컬럼1; // *조건문*

SELECT *
FROM instructor
LEFT JOIN teaches
ON instructor.id = teaches.id;
<RIGHT JOIN>
우측 테이블을 기준으로 일치하는 행만 결합되고, 일치하지 않는 부분은 null 값으로 채워진다.
[작성 형식]
SELECT *조회할컬럼*
FROM *비교대상_테이블*
RIGHT JOIN *기준_테이블*
ON B.컬럼1 = A.컬럼1; // *조건문*

SELECT *
FROM instructor
RIGHT JOIN teaches
ON instructor.id = teaches.id;
[INNER JOIN]
테이블1, 테이블2에서 SELECT된 컬럼이 공통적으로 존재하는 컬럼의 값만 결합해라.
[작성 형식]
SELECT *해당되는 모든 컬럼을 가져온다*
FROM 테이블1 (기준)
INNER JOIN 테이블2 (합쳐질_테이블)
ON 테이블1.공통적인_컬럼 = 테이블2.공통적인_컬럼;
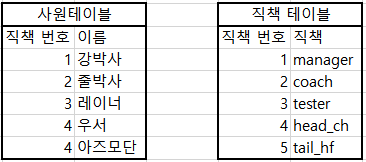
SELECT *
FROM 사원
INNER JOIN 직책
ON/WHERE 사원.직책 번호 = 직책.직책 번호;

15. <SQL GROUP BY> 키워드 : 데이터를 가져와서 어느 기준으로 정렬할지.
Q1. 국가별로 고객의 수를 나타내서 가져와라.
SELECT COUNT (CustomerID), Country // *컬럼1, 컬럼2
FROM 테이블
GROUP BY Country // *컬럼2*
Q2. 국가별로 고객이 많은 순으로 정렬해서 가져와라.SELECT COUNT (CustomerID), CountryFROM 테이블
GROUP BY Country
ORDER by COUNT (CustomerID) DESC;
16. <SQL HAVING> 키워드 // 레코드(row, 행)을 필터링하는 키워드. GROUP BY 뒤에 작성되어야 한다.
1. HAVING은 전체 결과에 대해 필터, WHERE은 개별 레코드(row,행)에 필터.
2. HAVING은 그룹화/집계 발생 이후 레코드를 필터, WHERE은 그룹화/집계 발생 이전 레코드를 필터
[HAVING 키워드 작성 양식]
SELECT 컬럼, 그룹함수(컬럼)
FROM 테이블
[WHERE 조건]
[GROUP BY GROUP대상]
[HAVING 그룹함수 포함조건]
[ORDER BY 정렬대상 ASC/DESC]
[SQL 그룹 함수]
| 함수명 | 기능 | 사용 |
| COUNT | 행의 수를 계산한다 | COUNT(컬럼) |
| MAX | 값들 중에 최대 값을 반환 | MAX(컬럼) |
| MIN | 값들 중에 최소 값을 반환 | MIN(컬럼) |
| AVG | 평균 값을 계산한다. | AVG(컬럼) |
| SUM | 총 합계를 계산한다. | SUM(컬럼) |
| VARIANCE | 분산을 계산한다. | VARIANCE(컬럼) |
| STDDEV | 표준편차를 계산한다. | STDDEV(컬럼) |
[SELECT문 실행 순서]
데이터를 조회하는 SELECT문의 실행/동작 순서.
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
EX)
SELECT CustomerId(컬럼1), AVG*그룹함수*(컬럼2) #5.
FROM invoices(테이블) #1.
WHERE CustomerId(컬럼1) >= 10 #2.
GROUP BY CustomerId (컬럼1) #3.
HAVING SUM*그룹함수*(Total) >= 30 #4.
ORDER BY 2 #6.
#1 : 대상 테이블에 접근.
#2. CustomerId 라는 컬럼이 10이상인 레코드를 조회.
#3. CustomerId를 기준으로 그룹화 한다.
#4. Total 이라는 컬럼의 총합이 30이상인 결과들만 필터링.
#5. 조회된 결과에서 CustomerId 컬럼과 Total 컬럼의 평균을 구함.
#6. AVG(Total) 필드를 기준으로 오름차순으로 정렬화한 결과를 리턴.
'백엔드 학습 과정 > Section 2 [재귀함수, 자료구조, 네트워크]' 카테고리의 다른 글
| Spring IoC / DI 에 관한 학습. // 추가 업뎃 예정 (1) | 2022.12.10 |
|---|---|
| #6-3. SQL 자가 학습 확인 문제들 (0) | 2022.12.08 |
| #6-1. DATABASE 생성 순서 (0) | 2022.12.05 |
| #6. 데이터베이스 - SQL, NoSQL, DB 설계 (0) | 2022.12.05 |
| #5. REST API - Richardson API 4단계 성숙도, 좋은 REST API 특징 (0) | 2022.12.04 |


